В этой статье поделимся экспериментом (опытом) написания скрипта в ИИ на языке программирования python (питон) для выгрузки данных из api поставщика svarog-rf.ru в файл.
Попалось на глаза простенькое api поставщика, где нет авторизации, множества функций и все работает просто. Один запрос дает список товаров с артикулами и ценами, остатками, второй запрос - по артикулу (ид) можно получить подробную информацию про конкретный товар. Мечта, а не api, поставщику респект за такое.
В качестве эксперимента в ИИ был отправлен запрос, состоящий из файла html страницы с документацией на api и просьбы сделать скрипт на питоне, который выгрузит информацию про товары с этого апи в csv файл.
Писать простенькие скрипты с ИИ приходилось и раньше, опыт разный и не однозначный, но этот случай уникален тем, что ИИ со второй(!) попытки выдал работоспособный скрипт, который выгрузил всю информацию о товарах в csv.

Копируем скрипт, запускаем его у себя и получаем спустя время результат.
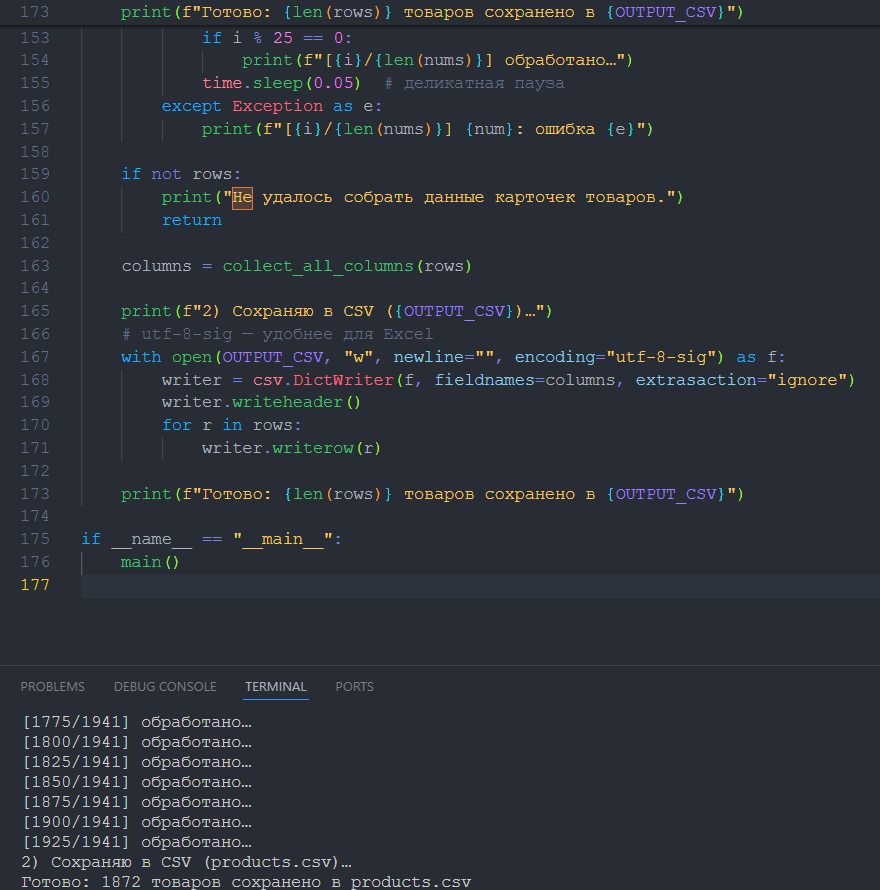
Все товары сохранились в csv:

Результат потрясающий. Полученный файл мы сможем без проблем загрузить в Прайсматрикс для дальнейшей обработки. И Прайсматрикс не нужно дорабатывать, чтобы грузить с этого api 🙂
Код самого скрипта, можно пользоваться:
import csv
import json
import re
import time
from typing import Dict, Any, List, Iterable
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
PRICELIST_URL = "https://svarog-rf.ru/api/pricelist"
PRODUCT_URL_TMPL = "https://svarog-rf.ru/api/products/{num}"
OUTPUT_CSV = "products.csv"
# --- сетап сессии с ретраями и таймаутами ---
def make_session() -> requests.Session:
s = requests.Session()
retries = Retry(
total=5,
backoff_factor=0.5,
status_forcelist=(429, 500, 502, 503, 504),
allowed_methods=frozenset(["GET"]),
raise_on_status=False,
)
s.headers.update({"User-Agent": "svarog-export-bot/1.0"})
s.mount("https://", HTTPAdapter(max_retries=retries))
s.mount("http://", HTTPAdapter(max_retries=retries))
return s
def sanitize_for_col(name: str) -> str:
"""Нормализуем заголовок колонки: пробелы -> _, убираем лишние символы."""
if name is None:
return ""
name = name.strip()
name = re.sub(r"\s+", "_", name)
name = re.sub(r"[^\w\-.:А-Яа-яЁё]", "_", name) # позволим кириллицу и цифры
return name
def join_list(values: Iterable[Any]) -> str:
return "|".join(map(lambda v: str(v).strip(), values)) if values else ""
def fetch_pricelist(session: requests.Session) -> List[Dict[str, Any]]:
resp = session.get(PRICELIST_URL, timeout=30)
resp.raise_for_status()
data = resp.json()
if not isinstance(data, list):
raise ValueError("Ожидался список от /api/pricelist")
return data
def fetch_product(session: requests.Session, num: str) -> Dict[str, Any]:
url = PRODUCT_URL_TMPL.format(num=num)
r = session.get(url, timeout=30)
if r.status_code == 404:
# товар отсутствует (например, временно исключён)
return {}
r.raise_for_status()
return r.json()
def flatten_product(p: Dict[str, Any]) -> Dict[str, Any]:
"""Плоская строка CSV из полной карточки товара."""
row: Dict[str, Any] = {}
# Базовые поля
for key in [
"num", "title", "category", "rr_price", "ma_price",
"in_stock", "outdated", "warranty", "url",
"description", "including", "spec_id"
]:
row[key] = p.get(key, "")
# Ярлыки
labels = p.get("labels") or []
row["labels"] = join_list(labels)
# Изображения
images = p.get("images") or []
row["images_count"] = len(images)
row["image_urls"] = join_list(img.get("url", "") for img in images)
row["image_titles"] = join_list(img.get("title", "") for img in images)
row["image_sizes"] = join_list(
f'{img.get("width","")}x{img.get("height","")}:{img.get("filesize","")}'
for img in images
)
# Документы
docs = p.get("documents") or []
row["documents_count"] = len(docs)
row["document_urls"] = join_list(doc.get("url", "") for doc in docs)
row["document_titles"] = join_list(doc.get("title", "") for doc in docs)
row["document_categories"] = join_list(doc.get("category", "") for doc in docs)
# Характеристики — и сводка, и по-колоночно с id
specs = p.get("spec_fields") or []
spec_summaries = []
for sf in specs:
title = sf.get("title", "")
units = sf.get("units") or ""
values = sf.get("value") or []
val_joined = ", ".join(map(str, values))
# сводная строка
spec_summaries.append(f"{title}: {val_joined}{(' ' + units) if units else ''}")
# колонка по id (стабильно) + названием (для удобства)
sid = sf.get("id")
if sid is not None:
col = f"spec_{sid}__{sanitize_for_col(title)}"
else:
col = f"spec__{sanitize_for_col(title)}"
row[col] = val_joined if not units else f"{val_joined} {units}"
row["specs"] = "; ".join(spec_summaries)
return row
def collect_all_columns(rows: List[Dict[str, Any]]) -> List[str]:
cols = []
seen = set()
# хотим стабильный порядок: базовые поля сначала
base_order = [
"num", "title", "category", "rr_price", "ma_price",
"in_stock", "outdated", "warranty", "labels",
"url", "description", "including",
"images_count", "image_urls", "image_titles", "image_sizes",
"documents_count", "document_urls", "document_titles", "document_categories",
"spec_id", "specs",
]
for c in base_order:
if c not in seen:
cols.append(c); seen.add(c)
# затем динамические spec_* и прочие поля, появившиеся у некоторых товаров
for row in rows:
for k in row.keys():
if k not in seen:
cols.append(k); seen.add(k)
return cols
def main():
session = make_session()
print("1) Загружаю прайс-лист…")
pricelist = fetch_pricelist(session)
nums = [item.get("num") for item in pricelist if item.get("num")]
print(f"Найдено товаров в прайс-листе: {len(nums)}")
rows: List[Dict[str, Any]] = []
for i, num in enumerate(nums, start=1):
try:
p = fetch_product(session, num)
if not p:
print(f"[{i}/{len(nums)}] {num}: нет данных (404)")
continue
row = flatten_product(p)
rows.append(row)
if i % 25 == 0:
print(f"[{i}/{len(nums)}] обработано…")
time.sleep(0.05) # деликатная пауза
except Exception as e:
print(f"[{i}/{len(nums)}] {num}: ошибка {e}")
if not rows:
print("Не удалось собрать данные карточек товаров.")
return
columns = collect_all_columns(rows)
print(f"2) Сохраняю в CSV ({OUTPUT_CSV})…")
# utf-8-sig — удобнее для Excel
with open(OUTPUT_CSV, "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=columns, extrasaction="ignore")
writer.writeheader()
for r in rows:
writer.writerow(r)
print(f"Готово: {len(rows)} товаров сохранено в {OUTPUT_CSV}")
if __name__ == "__main__":
main()
Или скачать можно по ссылке в текстовом файле: https://storage.catalogloader.com/screenshots/saa/2025-08-19-174245744--A10094I0pbO62K0N11009.txt